Microsoft’s research team has unveiled VALL-E 2, a new AI system for speech synthesis capable of generating “human-level performance” voices with just a few seconds of audio that were indistinguishable from the source.
“(VALL-E 2 is) the latest advancement in neural codec language models that marks a milestone in zero-shot text-to-speech synthesis (TTS), achieving human parity for the first time,” the research paper reads. The system builds on its predecessor, VALL-E, introduced in early 2023. Neural codec language models represent speech as sequences of code.
What sets VALL-E 2 apart from other voice cloning techniques is its “Repetition Aware Sampling” method and adaptive switching between sampling techniques, the team said. The strategies improve consistency and tackle the most common issues in traditional generative voice.
“VALL-E 2 consistently synthesizes high-quality speech, even for sentences that are traditionally challenging due to their complexity or repetitive phrases,” the researchers wrote, pointing out that the technology could help generate speech for people who lose the ability to talk.
As impressive as it is, however, the tool will not be made available to the public.
“Currently, we have no plans to incorporate VALL-E 2 into a product or expand access to the public,” Microsoft said in its ethics statement, noting that such tools bring risks like voice imitation without consent and the use of convincing AI voices in scams and other criminal activities.
The research team emphasized that there is a need for a standard method to digitally mark AI generations, recognizing that detecting AI-generated content with high accuracy still remains a challenge.
“If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model,” they wrote.
That said, VALL-E 2’s results are very accurate compared to other tools. In a series of tests carried out by the research team, VALL-E 2 outperformed human benchmarks in robustness, naturalness, and similarity of generated speech.
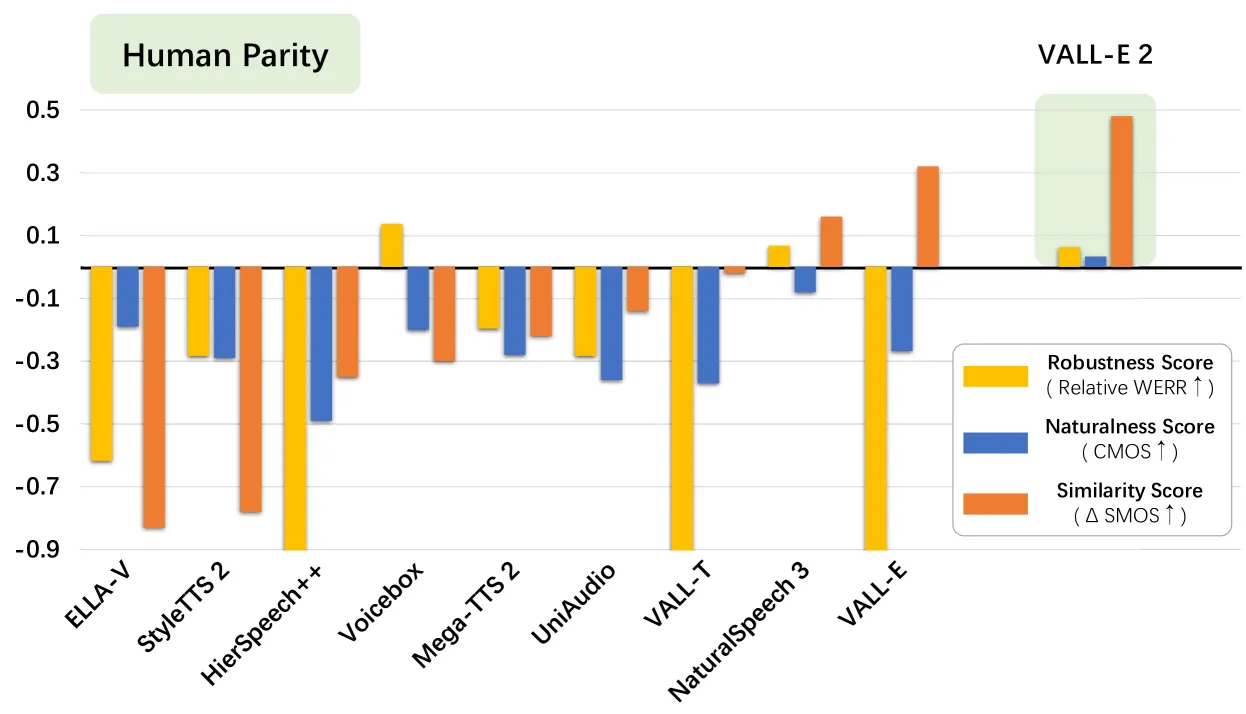
VALL-E-2 was able to achieve these results with just 3 seconds of audio. The research team noted, however, that “using 10-second speech samples resulted in even better quality.”
Microsoft is not the only AI company that has demonstrated cutting-edge AI models without releasing them. Meta’s Voicebox and OpenAI’s Voice Engine are two impressive voice cloners that also face similar restrictions.
“There are many exciting use cases for generative speech models, but because of the potential risks of misuse, we are not making the Voicebox model or code publicly available at this time,” a Meta AI spokesperson told Decrypt last year.
Also, OpenAI explained that it’s trying to first tackle the security issue before launching its synthetic voices model.
“In line with our approach to AI safety and our voluntary commitments, we are choosing to preview but not widely release this technology at this time,” OpenAI explained in an official blog post.
This call for ethical guidelines is spreading throughout the AI community, especially as regulators start to raise concerns about the impact of generative AI in our everyday lives.
Edited by Ryan Ozawa.

Microsoft’s research team has unveiled VALL-E 2, a new AI system for speech synthesis capable of generating “human-level performance” voices with just a few seconds of audio that were indistinguishable from the source.
“(VALL-E 2 is) the latest advancement in neural codec language models that marks a milestone in zero-shot text-to-speech synthesis (TTS), achieving human parity for the first time,” the research paper reads. The system builds on its predecessor, VALL-E, introduced in early 2023. Neural codec language models represent speech as sequences of code.
What sets VALL-E 2 apart from other voice cloning techniques is its “Repetition Aware Sampling” method and adaptive switching between sampling techniques, the team said. The strategies improve consistency and tackle the most common issues in traditional generative voice.
“VALL-E 2 consistently synthesizes high-quality speech, even for sentences that are traditionally challenging due to their complexity or repetitive phrases,” the researchers wrote, pointing out that the technology could help generate speech for people who lose the ability to talk.
As impressive as it is, however, the tool will not be made available to the public.
“Currently, we have no plans to incorporate VALL-E 2 into a product or expand access to the public,” Microsoft said in its ethics statement, noting that such tools bring risks like voice imitation without consent and the use of convincing AI voices in scams and other criminal activities.
The research team emphasized that there is a need for a standard method to digitally mark AI generations, recognizing that detecting AI-generated content with high accuracy still remains a challenge.
“If the model is generalized to unseen speakers in the real world, it should include a protocol to ensure that the speaker approves the use of their voice and a synthesized speech detection model,” they wrote.
That said, VALL-E 2’s results are very accurate compared to other tools. In a series of tests carried out by the research team, VALL-E 2 outperformed human benchmarks in robustness, naturalness, and similarity of generated speech.
VALL-E-2 was able to achieve these results with just 3 seconds of audio. The research team noted, however, that “using 10-second speech samples resulted in even better quality.”
Microsoft is not the only AI company that has demonstrated cutting-edge AI models without releasing them. Meta’s Voicebox and OpenAI’s Voice Engine are two impressive voice cloners that also face similar restrictions.
“There are many exciting use cases for generative speech models, but because of the potential risks of misuse, we are not making the Voicebox model or code publicly available at this time,” a Meta AI spokesperson told Decrypt last year.
Also, OpenAI explained that it’s trying to first tackle the security issue before launching its synthetic voices model.
“In line with our approach to AI safety and our voluntary commitments, we are choosing to preview but not widely release this technology at this time,” OpenAI explained in an official blog post.
This call for ethical guidelines is spreading throughout the AI community, especially as regulators start to raise concerns about the impact of generative AI in our everyday lives.
Edited by Ryan Ozawa.





